
Nella loro corsa per diventare una sorta di divinità onnisciente, i sistemi di intelligenza artificiale (IA) potrebbero consumare tutta la conoscenza gratuita disponibile su Internet già nel 2026, avverte un nuovo studio.
Modelli di intelligenza artificiale come GPT-4 o Claude 3 Opus si basano su trilioni di parole condivise online per diventare più intelligenti, ma nuove proiezioni suggeriscono che esauriranno la fornitura di dati disponibili al pubblico tra il 2026 e il 2032.
Ciò implica che, per sviluppare modelli migliori, le aziende tecnologiche dovranno cercare altre fonti di dati. Queste potrebbero includere la produzione di dati sintetici, il ricorso a fonti di qualità inferiore o, cosa più preoccupante, l’accesso a dati privati archiviati su server contenenti messaggi ed e-mail.
“Se i chatbot consumassero tutti i dati disponibili e non ci fossero progressi nell’efficienza dei dati, mi aspetterei di vedere una relativa stagnazione nel settore“, ha affermato Pablo Villalobos, autore principale di uno studio recentemente pubblicato sul server di prestampa arXiv. “I modelli miglioreranno solo lentamente nel tempo, man mano che verranno scoperte nuove intuizioni algoritmiche e nuovi dati verranno prodotti in modo naturale.”
L’importanza dei dati per l’IA
I dati di addestramento guidano la crescita dei sistemi di intelligenza artificiale, consentendo loro di identificare modelli sempre più complessi da integrare nelle loro reti neurali. Ad esempio, ChatGPT è stato addestrato su circa 570 GB di dati di testo, per un totale di circa 300 miliardi di parole, estratti da libri, articoli online, Wikipedia e altre fonti su Internet.
Gli algoritmi addestrati su dati insufficienti o di bassa qualità producono risultati dubbi. L’intelligenza artificiale senziente Gemini di Google, che consigliava di aggiungere colla alle pizze o di mangiare sassi, ad esempio, ha ottenuto alcune delle sue risposte più controverse da post su Reddit e articoli sul sito satirico The Onion.
Modelli affamati di dati
Per stimare la quantità di testo disponibile online, i ricercatori hanno utilizzato l’indice web di Google, stimando che attualmente ci siano circa 250 miliardi di pagine web con 7.000 byte di testo per pagina. Hanno poi eseguito l’analisi del traffico del protocollo Internet (IP) e dell’attività degli utenti online per prevedere la crescita di questo pool di dati.
I risultati hanno rivelato che le informazioni di alta qualità, estratte da fonti affidabili, si esauriranno entro il 2032, mentre i dati linguistici di bassa qualità saranno consumati tra il 2030 e il 2050. I dati di immagine, dal canto loro, si esauriranno tra il 2030 e il 2060.
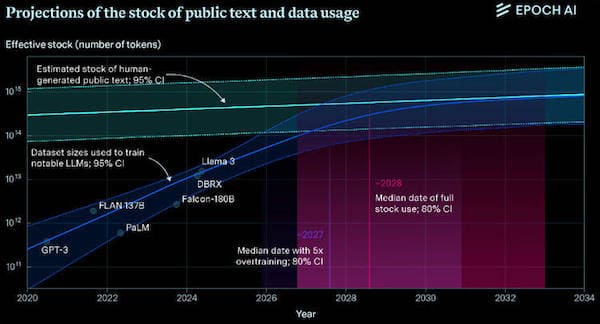
È stato dimostrato che le reti neurali migliorano in modo predittivo man mano che i loro set di dati crescono, un fenomeno chiamato legge di dimensionamento neurale. Pertanto, è una questione aperta se le aziende possano migliorare l’efficienza dei loro modelli per compensare la mancanza di dati nuovi, o se chiudere il rubinetto causerà una stagnazione dei miglioramenti del modello.
Tuttavia, Villalobos ha affermato che sembra improbabile che la scarsità di dati possa inibire drasticamente la crescita futura dei modelli di intelligenza artificiale. Questo perché esistono diverse possibili strategie che le aziende potrebbero utilizzare per aggirare il problema.
“Le aziende cercano sempre più di utilizzare i dati privati per addestrare modelli, come l’imminente cambiamento di politica di Meta“, ha aggiunto, riferendosi all’annuncio dell’azienda che utilizzerà le interazioni con i chatbot sulle sue piattaforme per addestrare la sua intelligenza artificiale generativa a partire dal 26 giugno.
“Se ci riuscissero, e se l’utilità dei dati privati fosse paragonabile a quella dei dati web pubblici, allora è molto probabile che le principali società di intelligenza artificiale disporranno di dati sufficienti per durare fino alla fine del decennio. A quel punto, altri ostacoli come il consumo energetico, l’aumento dei costi di formazione e la disponibilità dell’hardware potrebbero diventare più pressanti della mancanza di dati”.
Un’altra opzione è quella di utilizzare dati sintetici e generati artificialmente per alimentare i modelli affamati, sebbene ciò sia stato utilizzato con successo solo nei sistemi di formazione nei giochi, nella codifica e nella matematica.
In alternativa, se le aziende tentano di raccogliere proprietà intellettuale o informazioni private senza autorizzazione, alcuni esperti prevedono sfide legali.
“I creatori di contenuti hanno protestato contro l’uso non autorizzato dei loro contenuti per addestrare modelli di intelligenza artificiale, con alcune aziende che hanno citato in giudizio società come Microsoft, OpenAI e Stability AI“, ha scritto Rita Matulionyte, esperta di tecnologia e diritto della proprietà intellettuale e professore associato presso la Macquarie University in Australia, in un articolo su La Conversazione.
“Essere pagati per il proprio lavoro può aiutare a ripristinare parte dello squilibrio di potere che esiste tra i creativi e le aziende di intelligenza artificiale.”
Consumo di energia
I ricercatori sottolineano che la scarsità di dati non è l’unica sfida al miglioramento continuo dell’intelligenza artificiale. Secondo l’Agenzia Internazionale per l’Energia, le ricerche su Google basate su ChatGPT consumano quasi 10 volte più elettricità rispetto a una ricerca tradizionale.
Ciò ha portato i leader tecnologici a provare a sviluppare startup sulla fusione nucleare per alimentare i loro data center affamati, sebbene questo metodo di generazione di energia sia ancora lungi dall’essere praticabile.
A cura di Ufoalieni.it
Seguici su Telegram | Instagram | Facebook
© Riproduzione riservata
Riferimenti:
- Epoch AI – Un’analisi approfondita delle sfide nel futuro sviluppo dei modelli linguistici di grandi dimensioni (LLM), esplorando il potenziale esaurimento dei dati generati dall’uomo come limite alla loro scalabilità.
- Live Science – Un articolo che discute come i chatbot di intelligenza artificiale potrebbero consumare tutto il sapere scritto disponibile online entro il 2026, ponendo interrogativi sulle future fonti di apprendimento per questi modelli.